Correlation-Based Detection Rules in Cybersecurity: From Atomic Events to Behavioral Insight
- Category: CTI
- Source article: https://medium.com/@1200km/correlation-based-detection-rules-in-cybersecurity-from-atomic-events-to-behavioral-insigh-1b3df31597bb
- Published: 2025-12-02
- Preserved media: 1 image(s), including cover images, screenshots, diagrams, and infographics where present.
- Preserved technical blocks: 3 code/configuration block(s).
Ecosystem Fit
This page mirrors the original Medium article into the 1200km.com Docusaurus ecosystem. The original article flow, images, screenshots, infographics, and technical blocks are preserved from the export.
A comprehensive exploration of multi-event analytics, temporal logic, and rule chaining for advanced threat detection across modern SIEM and XDR ecosystems.
Introduction
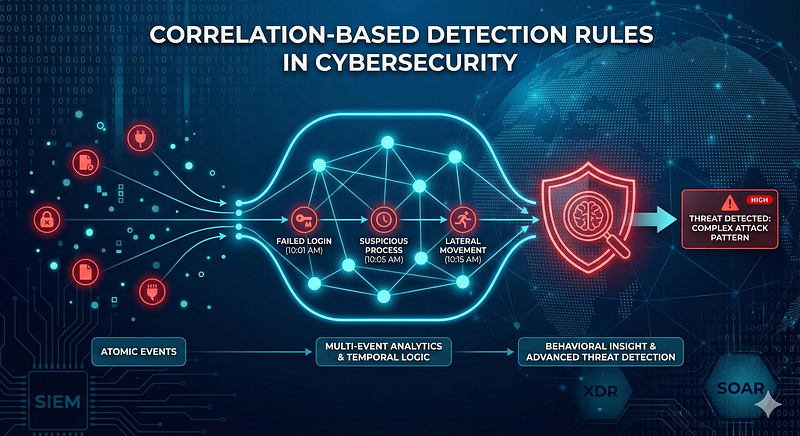
Correlation-based detection rules analyze relationships between multiple events across systems to identify attack patterns that single-event (atomic) rules cannot. Unlike an atomic rule that fires on one alert (e.g., a single malware signature match), correlation rules group and sequence log entries by shared attributes (user, host, IP, etc.) and time windows to uncover multi-step behaviors. In SIEM and security platforms, correlation provides context and reduces noise by linking related alerts. For example, a SIEM may correlate one failed login with other failed logins across accounts/IPs to reveal a brute-force attack. XDR/UEBA platforms similarly track entity behavior over time, building “living timelines” of user/device actions, so that even long-duration or stealthy attacks are detected. SOAR tools often consume correlated alerts for incident response.
Correlation rules differ from atomic rules in that atomic detections look at isolated events (often causing many false positives), whereas correlation rules require multiple conditions. As one Sigma detection expert notes, linking events by shared characteristics (such as grouping login failures by source IP or user) can reveal patterns a single event would not, and sharply reduce false positives. In contrast, treating each event “as a standalone snapshot” (as in stateless systems) fails to connect dots across time. In summary, correlation adds context (e.g. sequences, multi-system activity) and reduces alert noise, but at the cost of greater complexity, tuning effort, and potentially higher detection latency due to the need to observe multiple events.
Theoretical Foundations
**Event Correlation & Stateful Detection:**Correlation is formally “finding relationships between two or more log entries”. Conceptually, correlation is a form of stateful detection: the system “remembers” events and links them over time. A stateless (atomic) system treats each event independently; a stateful correlation engine maintains context about entities (users, hosts, sessions) across days or weeks. This state can be explicit (keeping match contexts or reference lists) or implicit (continuously updating risk scores or behavior profiles). Stateful detection allows building a narrative: for instance, Exabeam’s model tracks a user’s actions over an extended session, updating a risk score as each new event is added.
**Correlation Types:**There are several conceptual flavors of correlation in cybersecurity:
-
**Temporal/Sequence correlation:**Events that occur within a time window. This can be unordered (any order withintminutes) or ordered (event B must follow A). For example, a login failure followed by a success from the same user within 10 minutes is a temporal sequence rule. If ordering is enforced, it’s an “ordered temporal” rule.
-
**Threshold (Event Count) correlation:**Count of identical or similar events in a window. E.g., more thanNfailed logins for one account in 5 minutes.
-
**Value (Distinct Count) correlation:**Count of unique values of a field. For example, one IP address generating failed logins toMdifferent accounts in 10 minutes (password-spray detection).
-
**Entity-based correlation:**Aggregating all activity by a single entity (user or host) over time. For example, tracking every action by “Alice” to build a behavior profile. An alert might trigger if Alice’s behavior (processes, logins, data accesses) deviates from baseline. In practice, many correlation rules include grouping by
user.nameorhost.name. -
**Pattern/Rule Chaining:**Building higher-level correlations by chaining lower-level (atomic) rules. One rule’s trigger can feed another. For instance, Sigma correlation rules allow chaining: one rule fires on frequent failures, another on a following success, and a composite rule alerts only when both occur. This chaining (often implemented as DAGs of rules) enables detecting complex multi-stage tactics.
-
**Risk Scoring:**Rather than a simple rule outcome, some systems accumulate risk scores on entities. Each atomic or correlated alert adds to a user’s risk level. If the running score passes a threshold, an alert fires. This continuous-state approach (used in UEBA/XDR) effectively correlates events over long periods: a benign login that would not trigger an alert alone can contribute to a threat narrative when the user’s risk profile is already elevated.
-
**Machine Learning–Enhanced:**Correlation can be aided by ML models that identify anomalous patterns across many features. For example, Microsoft Sentinel’s “Fusion” uses ML to find unusual combinations of activities across the kill chain. Big-data SIEMs might cluster alerts or learn typical event sequences and then flag deviations.
**Architectures:**Correlation engines are typically built on normalized, schema-driven data (e.g. Elastic Common Schema, OCSF) so disparate logs share fields likeuser.name,host.ip, etc.. The architecture involves log ingestion → normalization (dedup, consistent format) → correlation rules engine → alert/ticket output. Rules engines may support stateful “sessions” or reference lists. Implicit state (like ArcSight “partial matches”) maintains a memory of past anchor events, which can be costly; explicit correlation (querying past events with joins or streams) is more scalable. Modern designs avoid unbounded memory: e.g., Sentinel’s Kusto queries use sliding-window joins with lookback to ensure no events are missed without saturating resources.
The use ofnormalized schemasis critical: correlating a VPN log with an endpoint log requires that common fields (likesource.ipvsclient.ip) be aligned. A consistent event model (such as OCSF) lets a single rule express logic across cloud, network, host, and identity events. Without normalization, correlation logic becomes brittle and siloed.
Detection Techniques
-
**Sequence-Based Rules:**Detect when Event A is followed by Event B on the same entity.*Example:*failed login events (IDS 4625) on a user followed by a successful login (4624) within 5 minutes. In pseudo-code:
if count(failed_logon by user) ≥ N and a success_login(user) occurs within T minutes → alert. In Sigma/Yara-L form, one might group “failed_logon” events by user, count ≥N over 10m, then chain to a “login_success” event. This catches classic brute-force breaks (MITRE T1110). -
**Time-Window Aggregation (Event/Value Count):**Detect high frequency of events in a window.Example:“More than 100 RDP login failures on any account in 10 minutes”. Formally,
group by account: if event_count(login_fail) > 100 in 10m → alert. Pseudocode (Sigma): -
type: event_count rules: [windows_logon_fail] group-by: [user.name] timespan: 10m condition: { gt: 100 -
This might map to T1110 (Password Spraying). Avalue_countvariant detects many distinct values: e.g., “One source IP causing 50 failed logins on different users (spraying)”.
-
**Entity-Centric Correlation:**Aggregate by identity or host to build context.Example:detect ifallactivity of a host or user is suspicious. For instance, “Within 1 hour, user Alice had logins from 3 different countriesandexecuted PowerShell scripts on two servers.” This often is implemented by filtering events by
user.nameand checking patterns. A Chronicle YARA-L example groups by user and counts unique cities: if “#distinct(city) > 1 within 5m”, it flags an impossible-travel anomaly. -
**Thresholds & Frequency:**Simple threshold rules form the basis of many correlation scenarios. These include generic rate/rule triggers: e.g. “10 failed SSH logins in 5 minutes” or “port scans: ≥100 ports probed from same IP in 1m”. These are essentially event_count rules.
-
**Risk Score Accumulation:**Instead of explicit event patterns, risk-based correlation adds weighted scores for multiple indicators on an entity. For example, a system might assign +10 risk for a suspicious file execution and +15 for a login anomaly on the same user; if the total exceeds 20, trigger. This effectively correlates disparate low-signal events into a high-risk scenario.
-
**ML-Enhanced Correlation:**Unsupervised or semi-supervised ML can dynamically cluster event sequences or score behaviors. Splunk ITSI/AIOps and Sentinel’s Fusion use such techniques: Fusion, e.g., correlates “anomalous” signals across stages of an attack using ML models.
-
**Rule Chaining (Atomic-to-Composite Logic):**Often, atomic detection rules are used as building blocks. A composite correlation rule might reference these by name. For example, one Sigma correlation YAML first defines a basic “failed_logon” rule; the correlation part then says “when this rule fires ≥N times in T, raise an alert”. Further chaining can link one correlation rule to another. Sekoia gives an example: first a rule “many_failed_logins” (if ≥5 failures in 10m), then a second rule triggers if “many_failed_logins” is followed by a successful login, ordered within 10m.
-
**Multi-Source Fusion:**Correlating events from different domains enhances detection.*Example:*an alert only if a user’s VPN login is followed (within minutes) by a suspicious executable on an endpoint. This requires linking an identity event and an endpoint event by a shared user or host. Sekoia’s Sigma docs show how aliases can map fields (e.g. IP as
internal_ip) across sources to correlate a “login_success” event on one system with a “new_connection” event on another.
**Query/Rule Examples:**Various platforms support these patterns. In Sigma correlation, a failed-login attack might be:
correlation:
type:
event_count
rules:
[
failed_logon
]
group-by:
[
TargetUserName
]
timespan:
5m
condition:
{
gte:
10
}
In Splunk SPL, one might use a stats/count over a search:
index=main EventID=
4625
| stats count
by
Account_Name, src
|
where
count >
50
In Chronicle YARA-L 2.0, a compound example is “different city logins”:
rule DifferentCityLogin {
events:
$e
.metadata.event_type =
"USER_LOGIN"
$e
.principal.user.userid =
$user
$e
.principal.location.city =
$city
condition:
$e
and
#city > 1 over 5m
}
This groups by$userand alerts if more than one distinct$cityappears in 5 minutes.
Each method above can be mapped to ATT&CK techniques where relevant. For instance, multiple failed logins = T1110 (Brute Force), fail-then-success login = T1078 (Valid Accounts) or T1110, account create/delete = T1136 (Create Account), unusual process chains = T1055/T1059, etc. Many open-source rule sets (SigmaHQ, Elastic, Chronicle YARA-L) provide correlating rules tagged with MITRE IDs for these scenarios.
Use Case Categories
Below are 15 illustrative attack scenarios best detected by correlation, with their log sources, sequence logic, MITRE IDs, and alert narrative examples:
-
**Brute-Force Login (T1110 — Brute Force):**Logs:Authentication logs (Windows, VPN, Linux, cloud identity).Sequence:≥N failed logins for the same user (or host) from one or multiple IPs withinTminutes, possibly ending in a success.*Detection:*Time-window aggregation: count failed logins grouped by user/IP.Example Rule:“User X had 20 failed SSH logins within 10m” triggers alert.Narrative:“Alert: Multiple failed login attempts detected — user ‘alice’ had 25 failed SSH login events in 10 minutes (Brute Force).”.
-
**Password Spraying (T1110.002 — Password Spraying):***Logs:*Authentication logs.*Sequence:*An IP address attempts logins on many accounts in a short period, often one try each (distinct account failures).*Detection:*Value-count correlation: group by source IP, count distinct target accounts failed.Example:“IP 10.0.0.5 had 40 distinct user login failures in 5m”.Narrative:“Alert: Possible password-spray — source IP 10.0.0.5 generated failed logins for 40 distinct user accounts over 5 minutes.”.
-
**Lateral Movement via Remote Services (T1021 series):***Logs:*Network logs (RDP, SMB, SSH), Windows Security (logon events).*Sequence:*Same user or credential successively logs onto multiple hosts, or sequence of logon on HostA then HostB.*Detection:*Entity correlation: correlate successful interactive logons by user across machines within a short window. Optionally chain with a suspicious process on target.Narrative:“Alert: Possible lateral movement — user ‘svcAccount’ logged into HOSTA then to HOSTB within 2 minutes.” (MITRE: T1021.001 RDP; or T1021.006 SSH).
-
**Reconnaissance and Scanning (T1046 — Network Service Scanning):***Logs:*Firewall, IDS/IPS, host firewall logs.*Sequence:*A host or IP hits many different destination IPs/ports in a time span.*Detection:*Threshold or value_count: group by source IP, count unique dest ports/IPs contacted in X minutes.Narrative:“Alert: Port scan — IP 10.1.2.3 connected to 150 unique ports across 10 hosts in 1 minute.”
-
**Privilege Escalation (T1068 — Exploitation for Privilege Gain):***Logs:*Windows event logs (service installation, new service creation), Sysmon (Process Create).*Sequence:*A user or process creates a new service or scheduled task with a known escalation signature (e.g. registry runkey in HKCU).*Detection:*Sequence rule: detect atomic “service installed” or “TaskScheduler new task” event, possibly chained with “admin group added” or suspicious process.Narrative:“Alert: Local admin elevation — new Windows service ‘xyz’ installed by user ‘bob’ and binary run in SYSTEM context.” (Relates to T1547/T1068).
-
**Account Creation and Deletion (T1136 — Create Account):***Logs:*Active Directory Security logs (EventIDs 4720, 4726), SaaS admin logs.*Sequence:*An account is created, used (maybe elevated actions), then deleted within hours.*Detection:*Correlate the creation event with a deletion event for the same username within a set window. For example, Sentinel KQL joins 4720 and 4726 for a matching UserName.Narrative:“Alert: New user ‘temp_admin’ created and removed within 3h; potential cover-up.”.
-
**Impossible Travel / Geo-Anomaly (T1078 — Valid Accounts):***Logs:*VPN or cloud login logs with geo/IP info.*Sequence:*Same user login from geographically distant locations within an unreasonably short time (e.g., login from US then Europe 10 minutes later).*Detection:*Temporal-spatial correlation: group logins by user and check distinct geolocations. Chronicle example: alert if a user’s logins have #cities >1 in 5m.Narrative:“Alert: Impossible travel — user ‘anna’ logged in from New York (10:00 AM) and Berlin (10:03 AM).”.
-
**Suspicious Process Chain (T1059 — Command and Scripting Interpreter):***Logs:*Sysmon/EDR logs (process creation).*Sequence:*A benign-looking parent process spawns a rarely used tool or scripting engine.*Detection:*Sequence rule: e.g., “Explorer.exe launches reg.exe” or “MSBuild.exe spawns PowerShell” within short time, where each on its own might be normal.Narrative:“Alert: Unusual process chain — user ‘alice’ ran cmd.exe which immediately spawned PowerShell with encoded commands.” (Possible T1059.001 execution).
-
**Data Staging/Exfiltration (T1074/T1041):***Logs:*File server access logs, DLP, cloud storage logs, network egress logs.*Sequence:*Large collection of data (e.g. many file reads on sensitive directories or large upload) followed by outbound transfer (HTTPS/FTP) or cloud upload.*Detection:*Correlate “file download/read” events on a file share and “network upload” to external IP, within a time window.Narrative:“Alert: Data exfiltration suspected — 200MB of files read on finance share by user X, followed by HTTPS upload to unknown IP.” (T1074.001 staging, T1041 Exfiltration).
-
**Insider Data Theft / Long Dwell (Various):***Logs:*Workstation, file access, database logs.*Sequence:*An internal user incrementally accesses sensitive data (e.g. many HR records, medical files) over days, then transfers them (USB or cloud).*Detection:*Entity-centric + accumulation: flag when an account accesses high volume of sensitive records and then performs a transfer. Combine threshold (e.g. >100 files in day) with context (sensitive share).Narrative:“Alert: Insider threat — privileged user copied 500 customer records over 2 days and then uploaded a ZIP to Google Drive.” (Often spans T1005 Data from Local Sys, T1567 Adversary-in-the-Middle exfil in cloud).
-
**Unusual Admin Activity (T1211 — Exploitation for Defense Evasion):***Logs:*Windows Security/EDS logs.*Sequence:*An admin account disables antivirus or enables PowerShell logging off.*Detection:*Correlation of two events: e.g. “MTA service stopped” and “Windows Defender disabled” by same account within minutes.Narrative:“Alert: Potential tampering — user Administrator stopped AV services and disabled Event Logging within 5 minutes.” (Defense Evasion techniques).
-
**Phishing Email + Click (T1566+T1204):***Logs:*Email gateway, proxy/web logs, endpoint (browser, process).*Sequence:*Receipt of email with malicious link, followed by the user’s browser visiting the URL or downloading payload.*Detection:*Correlate an email event (with malicious link or attachment) to a subsequent web download or process creation on that user’s machine within short time.Narrative:“Alert: Phishing chain — user received email with known-malicious URL, and 2 minutes later a process
evil.exelaunched on their host.” (Combines delivery T1566.001 and execution T1204.002). -
**Cloud Credential Misuse (T1078 — Valid Accounts):***Logs:*Cloud (AWS/Azure) logs, identity provider logs.*Sequence:*A high-value account (e.g. IAM admin) is used from an unusual source or for unusual API calls after normal working hours.*Detection:*Correlate login from an unknown IP plus unusual API activity (like changing security groups) by that user.Narrative:“Alert: Abnormal cloud login — admin ‘devops’ signed in from IP 8.x.x.x and immediately modified firewall rules.”
-
**Evil Component Deployment (T1574 — Hijack Execution Flow):***Logs:*Endpoint logs (file creation, DLL load), Sysmon.*Sequence:*Monitoring events shows a new service or WMI provider with code not signed by vendor. *Detection:*Correlate creation of service/WMI class with hash reputation (if low) or with its execution.Narrative:“Alert: Potential code injection — new service ‘MsUpdater’ installed with unsigned binary, loaded into memory.”
-
**RDP Brute-force on Admin (T1189 / T1110):***Logs:*RDP logs (EventID 4625), VPN logs if used.*Sequence:*Many failed RDP logons to an admin account from an external IP or TOR network, possibly followed by one success. *Detection:*Threshold rule on RDP failure events (group by IP/user) plus an optional success. Narrative:“Alert: RDP brute-force — 50 failed RDP logins for user ‘Administrator’ from IP X over 1h, followed by a successful logon.” (T1110 + T1189 External RDP).
Each scenario above would be implemented by a correlation rule linking the relevant events. In many cases the rule logic can be expressed in Sigma, YARA-L or SIEM query form as shown earlier. All examples include MITRE ATT&CK mappings for clarity.
Comparative Analysis
**Advantages of Correlation vs Atomic:**Correlation rules excel at detecting multi-step or low-signal attacks. By requiring a specific sequence or combination of events, they dramatically reduce alert noise and false positives compared to atomic rules. As noted in user space rule engineering, a single failed logon event alone is weak signal, but 10 such failures within minutes is highly suspicious. Indeed, studies have shown that effective correlation can cut alert volumes (and thus analyst fatigue) by over 80%. Correlation also provides richer context (linking events by user/asset) so that an alert’s narrative is clearer (e.g. “X then Y by user Z”), improving investigation speed. In layered detection architectures, correlation serves as a higher-fidelity filter built on atomic primitives.
**When Correlation Underperforms:**If misconfigured, correlation can miss attacks or introduce new gaps. Correlation inherently adds latency: you must wait for multiple events or a time window to expire before alerting. An attacker who moves extremely slowly or changes tactics may evade a time-bound rule. Also, overly strict correlation criteria (tight windows, many conditions) can lead to false negatives, while overly broad criteria cause false positives. Correlation logic can be fragile: missing logs or normalization errors break the chain. Performance is a concern — maintaining state or large sliding-window joins can consume memory and compute. For example, implicit SIEM correlation (tracking “open contexts” for anchors like each failed login for an hour) can overwhelm resources. In summary, correlated detection trades immediacy and simplicity for precision and context. Implementing many complex rules can increase storage and processing costs, and requires ongoing maintenance.
AspectAtomic RulesCorrelation RulesContextSingle-event; limited contextMulti-event; rich contextSignal StrengthOften low (single indicator)High (pattern of indicators)Alert VolumeTypically high (noisy)Typically lower (filtered, targeted)Complexity/CostLow (simple queries)Higher (stateful queries, chaining, tuning)LatencyImmediate (fires on event)Delayed (awaits events/window completion)Detection ScopeGood for isolated IOCs or exploitsGood for sequences/behaviors (multi-stage TTPs)
Best Practices
-
**Define Clear Use Cases:**Start with specific attack scenarios and threat models. Don’t blindly correlate everything; pick known TTP sequences (e.g. brute-force, APT kill-chains) and design targeted rules. As Infraon advises, know your goals (noise reduction, root cause, etc.) and pilot on small data sets before broad deployment.
-
**Leverage Atomic Rules as Building Blocks:**Implement atomic detection logic first (Sigma rules, YARA-L conditions) and then build correlation on top. Many frameworks (Sigma, Chronicle) allow referencing existing rule IDs in correlation rules. For example, use a base rule “failed_logon” and have a correlation rule count its occurrences.
-
**Use Structured Fields & Normalization:**Ensure events are normalized (e.g. ECS, OCSF). Group-by fields should be consistent; consider aliasing if needed (like matching
src_ipandsource.ip). Datadog notes that common schemas let you “write detection logic once” for any source. -
**Tune Thresholds and Windows:**Iteratively adjust counts and time spans. Periodically review each rule’s performance. If a rule is firing too often (false pos), tighten it; if it never triggers, relax it. As ManageEngine suggests, revisit rules when they’re “too broad” or “too limiting,” tweaking event sets or thresholds. Track metrics on alert counts pre/post tuning.
-
**Reduce False Positives/Negatives:**Add context filters where possible. For instance, correlate by userandsource IP or by asset group to avoid conflating unrelated events. Use allow/ignore lists (e.g. skip known benign accounts/IPs). Incorporate threat intel (e.g. only alert if an IP is on a blocklist) or geolocation context. For example, only flag city-anomaly logins if both cities are high-risk.
-
**Test and Simulate:**Validate correlation rules with real or simulated data. Atomic Red Team and purple-teaming exercises can generate correlated scenarios. Use logs replay or synthetic events to ensure a rule fires as intended. If your SIEM supports it, backfill or “dry run” alerts for a period to gauge false positives.
-
**Monitor Rule Health:**Keep track of each correlation rule’s alert rate over time. Sudden changes can indicate drift (logs changed format, new noise, or evasion). Archive or retire stale rules and update them as systems evolve. Document rule logic and assumptions clearly for future analysts.
-
**Enrichment & Context Injection:**Where possible, enrich logs before correlation. Add user risk scores, asset classification, or identity context. For example, tag events from C-suite accounts as high-importance, and have correlation rules raise more severe alerts for them. Inject geolocation or user department, so “cross-dept access + privilege change” can trigger a rule.
-
**Use the Right Tools:**Some correlation is easier in advanced platforms. For example, Splunk ITSI, Elastic Enterprise Search, or Chronicle have built-in correlation features. Cloud SIEMs (Azure Sentinel, Google Chronicle) offer rule chaining or ML fusions out of the box. Familiarize yourself with your platform’s capabilities (Kusto joins in Sentinel, EQL sequences in Elastic, YARA-L chains in Chronicle).
By following these practices, SOC teams can build robust correlation layers that complement atomic detections, enriching alerts with the needed context and reducing alert fatigue.
Real-World Case Studies
**Stealthy Account Cover-Up:**In one SOC incident, correlation of Windows Security events revealed a hidden attack: analysts joined EventID 4720 (account creation) and 4726 (account deletion) for the same user within hours. Neither event alone raised concern (account admins often add/delete users), but their sequence did. This mapped to MITRE T1136 (Create Account). The SIEM had a rule like the one in Azure Sentinel’s example: it joined creation and deletion events onTargetUserName, alerting on “deletionTime - creationTime < 24h”. The incident was flagged as a potentially malicious throwaway admin account. This correlation uncovered the attack that static rules (looking at one event type) had missed.
**Impossible Travel Phish:**A large enterprise used Chronicle SIEM, which had a YARA-L correlation rule for impossible travel (distinct cities within minutes). When a remote user’s credentials were phished, the attacker logged in from two countries in 8 minutes. The rule grouped by user and counted city values, triggering a high-severity alert (ATT&CK: initial access T1566, credential use T1078). Analysts confirmed the login events and blocked the session. Without this correlation (checking geolocation over time), the separate logins seemed benign.
**Multi-Stage Exploit Chain:**A security team deployed Sigma correlation rules for common exploits. One example (from SigmaHQ blog) monitored Confluence vulnerability (CVE-2023–22518): it triggered on an HTTP GET to the vulnerable endpoint and on spawning a shell process. By itself, “shell execution by process X” was low fidelity, but the correlation (“endpoint access” AND “shell spawn” within 10s) raised the alert to high severity. This mapped to MITRE T1190 (Exploit Public-Facing App) and T1059 (Command Execution). In practice, when penetration testers hit the Confluence bug, the SIEM generated a composite alert instead of two loose entries. The correlated alert narrative explicitly noted both actions, enabling quick response.
**APT Kill-Chain Correlation:**Elastic Security’s detection content often uses sequences. For instance, a multi-stage ransomware campaign was caught by layering: (1) a phishing email with an attachment (T1566), (2) execution of a Office macro (T1204.002), (3) abnormal PowerShell activity (T1059.001), and (4) file encryption alarms (T1486). The team wrote rules to link these stages by user and time: e.g., “phish email received by user U and within 5m process W attributed to U runs a known-downloader” (using a Sigma correlation and EQL in Elastic). This end-to-end correlation mapped alerts across ATT&CK phases from Initial Access to Impact. Each alert included a narrative tracing the stages, e.g. “User ‘jdoe’ opened a suspect macro and then spawned PowerShell downloadingevil.exe.” Without correlation, these might have been disjoint “phishing alert” and “Powershell anomaly” events.
These case studies illustrate that public detection frameworks (SigmaHQ, Elastic rules, Chronicle YARA-L, etc.) provide many correlation rule examples tagged to ATT&CK techniques. By implementing such rules, SOCs have uncovered stealthy threats that atomic signatures would miss.
Conclusions
Correlation-based detections are a crucial layer in modern defense-in-depth. They connect isolated alerts into coherent incidents, providing context that single-event rules cannot. In practice, a balanced detection strategy uses both: atomic rules for high-confidence individual actions (e.g. malicious file hashes, known exploits) and correlation rules to catch complex patterns (brute force, lateral movement, long-term campaigns). Correlation rules reduce noise and surface multi-stage threats, but they require careful design, robust normalization, and ongoing tuning. Detection engineers and SOC teams should therefore invest in building and maintaining a correlation rule repository, leveraging atomic detections as building blocks. Incorporating threat intel (e.g. ATT&CK mappings) and platform features (SPL joins, EQL sequences, YARA-L correlations) helps operationalize correlation logic. Ultimately, correlation enhances visibility across the kill chain. By systematically linking events, security teams can detect and stop attacks that fly under the radar of single-rule detection.