Attribution Methodology: How to Build, Defend, and Challenge a Threat Actor Attribution

- Category: CTI
- Source article: https://medium.com/@1200km/attribution-methodology-how-to-build-defend-and-challenge-a-threat-actor-attribution-071066437ced
- Published: 2026-03-20
- Preserved media: 11 image(s), including cover images, screenshots, diagrams, and infographics where present.
- Preserved technical blocks: 9 code/configuration block(s).
Ecosystem Fit
This page mirrors the original Medium article into the 1200km.com Docusaurus ecosystem. The original article flow, images, screenshots, infographics, and technical blocks are preserved from the export.
A practitioner’s guide for CTI analysts — from evidence collection to defensible conclusions
Table of Contents
-
Introduction: Why Attribution Is Hard and Why It Matters
-
The Attribution Spectrum
-
Evidence Type 1: IOC Overlap — Why It Is the Weakest Signal
-
Evidence Type 2: Infrastructure Reuse — Stronger, But Still Caveateable
-
Evidence Type 3: TTP Consistency — The Behavioral Fingerprint
-
Evidence Type 4: Operator Mistakes — The Strongest Evidence
-
The Attribution Confidence Model
-
Cluster-Level vs. Incident-Level Attribution
-
False Flags: When the Evidence Lies
-
Practical Exercise: Attributing APT29 / Cozy Bear / SVR
-
Splitting Findings: Confirmed / Assessed / Weak / Noise
-
How to Articulate Attribution — Valid and Uncertain
-
Common Attribution Mistakes
-
Attribution in Practice: Interview-Ready Frameworks
-
Quick Reference Cheatsheet
-
Conclusion
Introduction: Why Attribution Is Hard and Why It Matters
Attribution — the act of identifyingwhois behind a cyberattack — is one of the most difficult, consequential, and frequently misunderstood tasks in threat intelligence. It is difficult because skilled adversaries actively work to prevent it, because the digital environment provides enormous opportunity for deception, and because the evidence required for confident attribution is often partial, contradictory, or deliberately planted. It is consequential because attribution drives policy decisions, incident response priorities, sanctions, indictments, and military responses. It is misunderstood because the industry frequently presents attribution conclusions without the uncertainty qualifications those conclusions require.
This guide teaches attribution as ananalytical discipline, not a lookup operation. The goal is not to memorize which nation-state uses which malware family. The goal is to understandhowanalysts build attribution cases,what makes evidence strong or weak, andhow to communicate attribution conclusions with the epistemic honesty that separates credible intelligence from assertive noise.
What Attribution Actually Means
Attribution exists on a spectrum. At one end: “we observed an intrusion and know nothing about the actor.” At the other: “a named individual working for a specific government agency conducted this operation on a specific date” — the level of certainty reflected in a criminal indictment supported by years of signals intelligence.
Between those poles, most CTI attribution lives at the level ofcluster attribution: “these observed behaviors, tools, and infrastructure are consistent with a pattern we track as Group X, which we assess with medium-to-high confidence to be operating in support of Nation Y’s interests.”
Notice the qualifications in that sentence. They are not weakness. They are analytical integrity. An attribution statement without uncertainty bounds is not intelligence — it is an assertion.
Why Getting Attribution Wrong Is Worse Than Not Attributing
Wrong attribution has concrete consequences:
-
Incident response misdirection: if you attribute a financially-motivated actor to a nation-state, your response focuses on espionage containment instead of data theft prevention
-
Policy harm: incorrect nation-state attribution has historically been cited in diplomatic incidents
-
False flag success: if attackers plant evidence of another actor and you report that evidence as attribution, they achieve their deception objective
-
Credibility loss: a CTI team that over-attributes loses the trust of its consumers — and trust is the only currency intelligence has
The discipline of attribution methodology exists precisely to prevent these outcomes.
1. The Attribution Spectrum
Attribution does not snap between “unknown” and “attributed.” It moves along a spectrum that can be described as five levels:
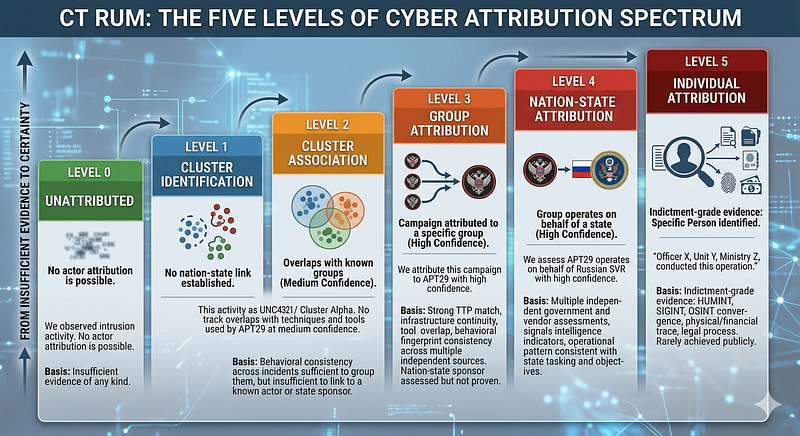
LEVEL
0
— UNATTRIBUTED
"We observed intrusion activity. No actor attribution is possible."
Basis: Insufficient evidence
of
any
kind.
LEVEL
1
-
CLUSTER IDENTIFICATION
"We track this as UNC4321 / Cluster Alpha. No nation-state link established."
Basis: Behavioral consistency across incidents sufficient
to
group
them,
but insufficient
to
link
to
a known actor
or
state sponsor.
LEVEL
2
-
CLUSTER ASSOCIATION
"This activity overlaps with techniques and tools used by APT29 at medium confidence."
Basis: TTP overlap,
some
infrastructure
intersection
with
a known group.
Association,
not
identification.
LEVEL
3
-
GROUP
ATTRIBUTION
"We attribute this campaign to APT29 with high confidence."
Basis: Strong TTP
match
, infrastructure continuity, tool overlap, behavioral
fingerprint consistency across multiple independent sources.
Nation
-
state sponsor assessed but
not
proven.
LEVEL
4
-
NATION
-
STATE ATTRIBUTION
"We assess APT29 operates on behalf of Russian SVR with high confidence."
Basis: Multiple independent government
and
vendor assessments, signals
intelligence indicators, operational
pattern
consistent
with
state
tasking
and
objectives.
LEVEL
5
-
INDIVIDUAL ATTRIBUTION
"Officer X, Unit Y, Ministry Z, conducted this operation."
Basis: Indictment
-
grade evidence: HUMINT, SIGINT, OSINT convergence,
physical
/
financial trace, legal process. Rarely achieved publicly.
Most CTI work operates between Levels 2 and 4. Level 5 requires resources and access that very few organizations possess. The goal of a CTI analyst is to be honest about which level their evidence supports — and to resist the organizational or media pressure to claim a higher level than the evidence warrants.
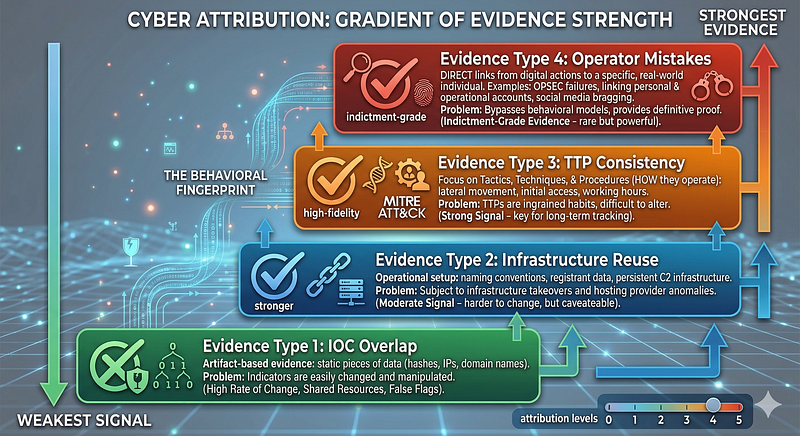
2. Evidence Type 1: IOC Overlap — Why It Is the Weakest Signal
What It Is
IOC (Indicator of Compromise) overlap attribution is the practice of linking two incidents or campaigns because they share technical indicators: the same IP address, the same domain, the same file hash, the same SSL certificate.
“We saw the same C2 IP address in Campaign A (attributed to APT29) and Campaign B (unattributed). Therefore Campaign B is APT29.”
This is the most common and most problematic form of attribution reasoning in the industry.
Why It Is Weak
**IP addresses are not identity documents.**A single IP address may be:
-
A shared hosting provider used by thousands of customers
-
A VPN exit node or Tor relay used by anyone
-
A compromised legitimate server (the victim becomes the accused)
-
A commercially available bulletproof hosting service sold to multiple actors
-
Infrastructure that was acquired, used, abandoned, and then acquired by a different actor
**Domains decay and transfer.**A domain used by Actor X in 2022 may be abandoned, allowed to expire, re-registered by Actor Y in 2023, and then used in a completely unrelated campaign. Attributing the 2023 campaign to Actor X based on domain overlap is incorrect — and happens constantly in industry reporting.
**File hashes can be copied.**Open-source tools, leaked malware source code, and commodity crimeware are used across hundreds of actors. Detecting Mimikatz, Cobalt Strike, or Metasploit tells you nothing about attribution. Even more sophisticated malware families have had their source code leaked (Mirai, Conti, LockBit) and subsequently used by unrelated actors.
**False flag potential is high.**IOCs are the easiest element of an operation to plant. An attacker who wants to be attributed to a different group simply needs to use that group’s known infrastructure or tools. Olympic Destroyer (covered in detail below) is the canonical example.
When IOC Overlap Is Useful
IOC overlap is not worthless — it is acollection trigger, not an attribution conclusion:
-
An IOC overlap with a known actor profile tells you: “investigate this incident more carefully for other evidence of that actor”
-
It is a starting point, never an endpoint
-
When IOC overlap iscombinedwith TTP consistency and additional corroboration, it contributes to a cumulative case
**The analyst rule:**Never write “we attribute this to [Actor] based on shared infrastructure.” Always write “shared infrastructure with [Actor]’s known C2 infrastructure was observed; this is a collection trigger requiring further corroboration.”
3. Evidence Type 2: Infrastructure Reuse — Stronger, But Still Caveatable
What It Is
Infrastructure reuse attribution examines patterns in how an actor builds, manages, and operates their technical infrastructure over time. Unlike simple IOC overlap (same IP), infrastructure reuse looks at:
-
Hosting patterns: Which ASNs, hosting providers, countries, and payment methods does the actor prefer?
-
Certificate patterns: Does the actor reuse SSL certificates, self-sign with consistent parameters, or use specific certificate authorities?
-
Registration patterns: Do domains registered for campaigns share registration timing, registrar, privacy service, or naming conventions?
-
Network fingerprinting: Does the actor’s C2 infrastructure respond with consistent server headers, TLS fingerprints (JA3/JA3S), or banner patterns?
-
Operational infrastructure lifecycle: How long does the actor maintain infrastructure before retiring it? Do they burn it immediately after use or maintain it for months?
Why It Is Stronger Than Simple IOC Overlap
Infrastructure analysis looks atbehavioral patterns, not individual indicators. Even when an actor rotates specific IPs and domains (as all sophisticated actors do), their infrastructuremanagement behavioroften remains consistent. This is because:
-
**Operational habits are hard to change.**An actor who has always registered domains through Namecheap with privacy protection, hosted on OVH, and used self-signed certificates with a 365-day validity will likely continue doing so across campaigns because it is what they know.
-
**Infrastructure provisioning requires money and process.**Payment methods, cryptocurrency wallets, and purchasing patterns leave traces across campaigns that are harder to deliberately vary than individual indicators.
-
**JA3/JA3S fingerprints are stable.**A specific C2 framework configured in a specific way produces consistent TLS fingerprints even when the IP changes. Cobalt Strike with custom malleable profiles, Sliver, Brute Ratel — all produce distinguishable fingerprints.
Infrastructure Reuse in Practice: What Analysts Look For
Passive DNS analysis: Tools like PassiveTotal, SecurityTrails, and Shodan index historical DNS resolution data. If a domain suspected in Campaign B resolves to an IP block that previously hosted known-malicious infrastructure from Campaign A, that is meaningful — especially if the hosting pattern (registrar, ASN, server software version) is consistent.
Certificate transparency logs: CT logs record every publicly issued TLS certificate. An actor who registers multiple domains for an operation often does so in rapid succession, creating a timestamp cluster visible in CT logs. Certificate subject fields, SANs, and issuance timing provide fingerprinting data.
Shodan/FOFA/Censys infrastructure fingerprinting: Scanning the open internet for specific HTTP response headers, TLS configurations, or port combinations that match known C2 frameworks allows analysts to identify previously-unknown actor infrastructure based on its fingerprint profile.
Why It Remains Caveatable
-
**Shared hosting means shared fingerprints.**If two actors use the same VPS provider, their infrastructure may appear similar even though they are unrelated.
-
**Tool-sharing means shared C2 profiles.**If two groups use the same Cobalt Strike Malleable C2 profile (common with shared tool kits), their JA3 fingerprints may match without being the same actor.
-
**False flags extend to infrastructure.**An actor who wants to implicate another group can deliberately register domains and set up infrastructure that matches that group’s known patterns.
**The analyst rule:**Infrastructure overlap should be presented as “consistent with Actor X’s known infrastructure provisioning patterns” — not as “the same actor.” Document specificallywhichinfrastructure characteristics match andhow rarethose characteristics are. Rare patterns carry more weight than common ones.
4. Evidence Type 3: TTP Consistency — The Behavioral Fingerprint
What It Is
TTP (Tactics, Techniques, and Procedures) consistency is the comparison ofhowan actor operates across multiple campaigns. It is the most reliable non-mistake attribution evidence because:
-
**Tools and procedures are operationally expensive to change.**An actor who has spent years developing, testing, and refining a custom tool chain does not abandon it easily. Retooling requires investment, introduces risk of operational failures, and requires retraining operators.
-
**Behavioral habits are subconscious.**The sequence in which an actor performs reconnaissance, the specific flags they pass to their tools, the way they name their payloads, the order of their lateral movement steps — these reflect operator training and habit, not deliberate choices that can easily be varied.
-
**Custom tooling is uniquely attributable.**When an actor develops a custom backdoor or implant, that code carries characteristics (compilation artifacts, string patterns, encryption implementations, error-handling logic) that are essentially unique. Finding the same custom code in two campaigns is strong attribution evidence.
The Layers of TTP Analysis
**Layer 1 — Tool fingerprinting (unique tools)**The presence of a custom or rare tool is high-value. If Campaign A and Campaign B both use the same custom backdoor with the same embedded configuration format, the same encrypted communication protocol, and the same in-memory execution technique, the probability that these are unrelated actors is very low.
Examples:
-
SUNBURST (APT29/SolarWinds): unique SolarWinds Orion DLL implant with distinctive obfuscation and communication logic
-
Industroyer (Sandworm): unique ICS protocol implementation with specific SCADA command structure
-
PlugX variants: actor-specific configurations embedded in shared RAT code
Layer 2 — Operational pattern consistencyHow does the actor move through an environment? The sequence of:
- Initial access method → lateral movement method → credential access approach → C2 establishment → collection behavior constitutes an operational fingerprint. Sophisticated analysts track these sequences across incidents.
Example: Actor X consistently uses spearphishing → macro execution → PowerShell download cradle → specific C2 framework → NTDS dump → PsExec lateral movement. When a new incident shows this exact chain, TTP consistency is a strong attribution signal.
Layer 3 — Living-off-the-land preference and selectionActors that prefer LOTL techniques still leave fingerprints inwhichLOTL tools they use andhowthey use them. An actor who consistently usesnltest /dclist:for domain controller discovery,wmic /node: process call createfor lateral movement, andvssadmin create shadow /for=C:for credential access has a behavioral fingerprint even when using only native Windows tools.
Layer 4 — Targeting and tasking patternWhat sectors does the actor target? What data do they collect? What is the timing of their operations relative to geopolitical events? An actor that consistently targets aerospace and defense organizations, operates primarily during specific business hours, and collects documents related to military procurement is demonstrating tasking consistency that suggests a specific intelligence requirement — and therefore a specific sponsor.
Limits of TTP Attribution
-
Tool sharing and acquisition: Nation-state actors have been observed sharing tools with allied groups, selling access to their infrastructure, and re-using publicly leaked malware. APT41’s use of ransomware tools alongside espionage tools initially confounded attribution.
-
Deliberate TTP mimicry: A sophisticated actor who wants to frame another group can study and replicate their procedures — to a degree. This is much harder than planting IOCs, but not impossible.
-
Framework overlap: Cobalt Strike, Metasploit, and Sliver are used by hundreds of groups. Detection of these tools provides zero attribution without additional TTP specifics.
**The analyst rule:**When reporting TTP consistency, specifywhichTTPs are consistent,how manyindependent incidents demonstrate the consistency, andhow distinctivethose TTPs are (common LOTL tools carry less weight than unique custom tooling).
5. Evidence Type 4: Operator Mistakes — The Strongest Evidence
What It Is
Operator mistakes are unintentional disclosures — moments when the humans behind an operation violated their own operational security and exposed identifying information. Unlike other evidence types that can be fabricated or shared, genuine operator mistakes are extremely difficult to fake convincingly — they require an adversary to deliberately simulate their own OPSEC failure in a way that produces authentic-looking identifying information.
This makes operator mistakes the gold standard of attribution evidence, when they can be found.
Categories of Operator Mistakes
Category 1: Language and Locale Artifacts
Malware compiled on a machine with specific locale settings embeds those settings in compilation artifacts:
-
Compiler timezone: PE files embed a compilation timestamp. If the timestamp is consistent with Moscow Standard Time business hours across dozens of samples, that is a timezone attribution signal.
-
Keyboard layout artifacts: Typos consistent with a specific keyboard layout, autocorrect artifacts from a specific language setting, or characters from a non-English character set embedded in strings.
-
Metadata language: Office documents used as lures or droppers often contain Author fields, revision history, and language metadata from the author’s system. Russian-language Author fields in phishing documents attributed to Russian actors are not coincidences.
-
Error messages in native language: Operators who write custom tooling sometimes leave error messages, debug strings, or comments in their native language — either through oversight or because the tool was originally written for internal use.
**Real example — WannaCry (Lazarus Group):**The English ransom note in WannaCry contained grammatical patterns consistent with a non-native English speaker translating from Korean. The Korean-language ransom note, by contrast, was written with native fluency. This linguistic analysis contributed to the attribution to North Korean operators.
Category 2: Working Hours and Timezone Consistency
Across a campaign, the timestamps of malware compilation, C2 activity, and operator interactions cluster within specific hours. If:
-
Malware samples are consistently compiled between 09:00–18:00 UTC+3
-
C2 beacon responses occur primarily during weekday business hours
-
Operational pauses align with public holidays in a specific country
…these patterns, observed consistently across months of activity, are strong circumstantial evidence of operator timezone and working schedule. Nation-states’ threat groups generally operate like offices: working hours, weekends off, national holidays respected.
**Real example — APT28 (Fancy Bear):**Analysis of APT28 malware compilation timestamps, C2 activity logs, and operational pauses showed clustering consistent with Moscow timezone business hours, with clear activity reduction on Russian national holidays.
Category 3: OPSEC Failures — Direct Personal Exposure
Operators who momentarily fail to route traffic through their anonymization layer expose their real IP addresses. These real IPs have appeared in:
-
VPN connection logs from compromised infrastructure
-
Failed authentication attempts from a real IP before the VPN connected
-
Debugging sessions where the attacker tested from their real network
-
Automated tools that briefly connected without the expected proxy chain
**Real example — APT29 (Cozy Bear/SVR):**During the SolarWinds investigation, MSTIC identified moments where SVR operators connected to victim environments from infrastructure that could be traced through ASN analysis and historical passive DNS to Russian internet service providers and ASNs previously associated with SVR activity — including one IP block assigned to an organization in Skolkovo.
Category 4: Code Reuse and Unique Implementation Choices
When a developer writes a custom cryptographic implementation, a custom compression algorithm, or a unique communication protocol, they make hundreds of micro-decisions about implementation. These decisions — the choice of byte ordering, the specific constants used, the error handling approach, the buffer allocation pattern — constitute a coding fingerprint.
When the same unique implementation appears in malware from Campaign A and Campaign B, separated by years, the probability that two different developers independently made the same hundreds of micro-decisions is essentially zero.
**Real example — Olympic Destroyer vs. Lazarus Group:**Olympic Destroyer (deployed during the 2018 Pyeongchang Olympics) contained a code similarity score of 98.5% with known Lazarus Group malware when measured on multiple static analysis dimensions. The similarity wasdeliberate— it was a planted false flag. But what made this attribution mistake detectable was deeper analysis: theunique code elementsthat differed from Lazarus’s actual implementation pattern were inconsistent with how Lazarus actually wrote code. Kaspersky Lab’s analysts recognized that a perfect-looking match was itself a red flag.
Category 5: Personnel Linkages — The Rarest and Most Valuable
Occasionally, open-source research links operational infrastructure to real individuals:
-
Email addresses used to register C2 domains appear in breached credential databases or developer forums
-
GitHub, GitLab, or VirusTotal accounts used to test malware samples are linked to real identities
-
LinkedIn or professional profiles of individuals with the relevant technical background employed by relevant government organizations
-
Financial traces: cryptocurrency wallets used to pay for infrastructure, when traced, sometimes connect to exchanges that have KYC records
**Real example — GRU Unit 74455 (Sandworm):**The U.S. DOJ indictment of Sandworm officers in 2020 was built in part from OSINT linkages: email addresses used to register operational infrastructure appeared in other contexts connected to real individuals. The indictment named six specific GRU officers by name, rank, and unit assignment.
Why Operator Mistakes Are the Strongest Evidence
They arehard to fake:
-
A false-flag operation that wants to implicate Russian operators would need to:
-
Compile malware on a machine configured with Russian locale at Moscow business hours consistently over months
-
Use an IP address with a traceable chain to Russian infrastructure without making that trace look planted
-
Produce coding artifacts consistent with Russian operator training and tool development history
-
Leave personal metadata consistent with a real Russian person
Each layer of fake operator mistakes requires increasing sophistication and introduces risk of detection. Genuine operator mistakes, by contrast, are unintentional — they appear exactly as authentic because they are.
6. The Attribution Confidence Model
A robust CTI attribution uses a structured confidence model. Without it, “high confidence” from one analyst means something different than “high confidence” from another, and intelligence consumers cannot calibrate how much weight to give conclusions.
Three-Tier Confidence Framework

Applying the Model
Every attribution statement should carry an explicit confidence label and a brief rationale:
Correct:“We attribute this campaign to APT29 with high confidence, based on: (1) consistent use of SUNSHUTTLE and EnvyScout malware exclusively associated with this group, (2) operational pattern matching across three independent incidents, and (3) infrastructure provisioning patterns consistent with SVR-associated hosting preferences. Residual uncertainty: we cannot independently confirm nation-state tasking direction beyond open-source attribution by CISA and NSA.”
Incorrect:“This attack was carried out by Russian hackers.”
7. Cluster-Level vs. Incident-Level Attribution
One of the most important and most frequently conflated distinctions in attribution is betweencluster-levelandincident-levelattribution.
Cluster-Level Attribution
A cluster is a group of incidents, tools, and infrastructure that have been assessed to share a common operator or operator group based on behavioral consistency. Cluster-level attribution says:“These activities are connected. We track them together.”
Cluster-level attribution is achievable with moderate evidence: TTP consistency across multiple campaigns, infrastructure overlap patterns, shared tooling. It does not require knowing who the operator is — only that the same pattern recurs.
Examples of cluster IDs used across vendors:
-
UNC4396,DEV-0978,TA455— uncharacterized clusters using numeric/alphanumeric IDs -
APT29,NOBELIUM— named groups with assessed nation-state attribution
A cluster ID is a tracking label. It does not assert anything about identity — only about behavioral grouping.
Incident-Level Attribution
Incident-level attribution says:“This specific intrusion was conducted by Actor X.”
This is much harder to prove than cluster-level attribution and requires:
-
Evidence that Actor X’s specific tooling was used (not just tooling consistent with Actor X’s profile)
-
Evidence that Actor X had the access and opportunity to conduct this specific incident
-
Absence of evidence that Actor X’s tools were available to or used by other actors in this context
The failure to distinguish cluster from incident attribution is behind many high-profile attribution errors.Cluster-level attribution does not automatically mean incident-level attribution.
The Crosswalk Problem
When Vendor A tracks a cluster as “APT29,” Vendor B tracks it as “NOBELIUM,” and Vendor C tracks it as “Cozy Bear,” they may or may not be tracking the same underlying activity. Cross-vendor naming convergence at the cluster level is common. Cross-vendor agreement onevery incidentattributed to that cluster is much rarer — because different vendors have different evidence sets and different clustering decisions.
When you use an actor’s name in a CTI report, be explicit about which vendor’s tracking definition you are using, and acknowledge that cross-vendor boundaries may not be identical.
8. False Flags: When the Evidence Lies
What a False Flag Is
A false flag is a deliberate attempt by an attacker to make their operation appear to come from a different actor. The attacker plants evidence — IOCs, code similarities, language artifacts, or operational patterns — that points attribution toward an innocent third party.
False flags are not theoretical. They have been executed by sophisticated nation-state actors and discovered (sometimes years later) by analysts.
The Olympic Destroyer Case Study
**What happened:**During the 2018 PyeongChang Winter Olympics, a destructive wiper was deployed against the Olympic Games IT infrastructure. The malware was initially attributed by multiple vendors to North Korea (Lazarus Group) due to a very high code similarity score to known Lazarus tooling.
**What was actually happening:**Kaspersky Lab’s investigation discovered that the code similarity wasartificially constructed. The Olympic Destroyer malware had been deliberately engineered to contain code elements matching Lazarus Group’s signature, but when analyzed at a deeper level, the actual implementation logic, error handling, and operator artifact patterns were inconsistent with how Lazarus actually wrote code. The false flag was sophisticated but detectable by analysts who knew Lazarus’s coding style deeply enough to recognize a counterfeit.
**The ultimate attribution:**The false flag was assessed to have been planted by Sandworm (Russia/GRU), who were responsible for the actual attack. The false flag was intended to attribute the Olympics disruption to North Korea, politically protecting Russia.
**The lesson:**High code similarity scores are not sufficient for attribution when the similarity could be artificially constructed. Thequalityandauthenticityof the matching must be assessed, not just the quantity of matched bytes.
Detecting False Flags
**Examine the plausibility of the evidence chain.**Ask: does it make sense for the ostensibly attributed actor to target this victim, at this time, for this purpose? Attribution that defies the actor’s established operational logic deserves more scrutiny.
**Look for evidence that is suspiciously convenient.**Real operators make mistakes accidentally. Evidence that appears to be a perfectly placed “mistake” — a file that is easy to find, in an obvious location, matching exactly the known IOC pattern of a target actor — may be planted.
**Check for evidence inconsistencies at depth.**Surface-level IOC and code similarity can be fabricated. Deep behavioral analysis — compilation environment artifacts, operator workflow sequence, timing patterns — is much harder to fake convincingly. If the surface evidence strongly implies Actor X but the deep behavioral evidence is inconsistent with Actor X’s known patterns, the surface evidence may be a false flag.
**Apply the geopolitical plausibility filter.**Does the operation’s timing, targeting, and apparent objective align with the attributed actor’s known strategic interests? If it doesn’t, add a false flag assessment explicitly to your report.
9. Practical Exercise: Attributing APT29 / Cozy Bear / SVR

Why APT29 for This Exercise
APT29 (also tracked as Cozy Bear, NOBELIUM, Midnight Blizzard, The Dukes) is the most comprehensively documented attribution case in the public record. Over twenty years of operations, multiple government indictments and formal attributions, and extensive vendor analysis provide a rich evidence base across all four evidence types. It is the ideal case study for learning attribution methodology.
Formal attributions (Level 4 — Nation-State):
-
U.S. CISA, NSA, FBI, NCSC (UK): formally attributed SolarWinds campaign to SVR (2021)
-
NCSC UK formally attributed multiple APT29 campaigns to SVR (2018–present)
-
Dutch AIVD: publicly attributed APT29 to Russian intelligence (2017)
The Evidence Base: All Four Types Demonstrated
IOC Evidence (Weak alone — used as collection trigger)
APT29 has used specific IP ranges, C2 domains, and file hashes documented in:
-
CISA Alert AA21–008A (SolarWinds)
-
FireEye/Mandiant “Highly Evasive Attacker Leverages SolarWinds Supply Chain” (2020)
-
NCSC UK APT29 advisory (2020)
**Analyst note:**These IOCs rotate across campaigns. The IP185.225.17[.]5or the domainavsvmcloud[.]comare useful for detection and retrospective hunting but would not support attribution in isolation. They are starting points for investigation.
Infrastructure Reuse Evidence (⚠supports the case)
Across multiple APT29 campaigns, consistent infrastructure patterns include:
-
Preference for US-based cloud hosting providers (Amazon AWS, Microsoft Azure, Cloudflare) for C2 — making traffic blend with legitimate business traffic
-
Use of compromised third-party infrastructure (universities, small businesses, government contractors) as hop points — rather than direct actor-owned C2
-
TLS certificate practices: short-validity certificates renewed on a predictable schedule, consistent with automated certificate management
-
Domain registration patterns: .com / .net domains with privacy protection, registered via European registrars, often mimicking legitimate software vendor or security company names
The consistency of these patterns across the 2014 DNC breach, the 2016 election interference campaign, the 2020 SolarWinds supply chain attack, and the 2023 Microsoft corporate email breach demonstrates that infrastructure provisioningstyleis stable even as specific indicators rotate.
TTP Consistency Evidence (strong)
APT29’s TTP fingerprint is one of the most distinctive in the public record:
**Unique tooling lineage:**The “Dukes” malware family (MiniDuke, CosmicDuke, OnionDuke, HammerDuke, CloudDuke) represents a continuous development lineage with shared code elements, similar encryption schemes, and consistent C2 communication structures maintained across a decade. No other actor has been observed using this tooling.
**SolarWinds: the SUNBURST supply chain technique:**The modification of a legitimate SolarWinds Orion DLL (SolarWinds.Orion.Core.BusinessLayer.dll) to include a dormant backdoor that activated only after a 12–14 day delay, checked for domain-joined system status, verified it was not running in an analysis environment, and communicated via legitimate SolarWinds API call patterns — represents a level of operational sophistication and patience consistent with a well-resourced state actor. The technique (supply chain implant with dormancy and environment checking) is a TTP fingerprint.
**WELLMESS and WELLMAIL:**Custom Go-language malware used exclusively by APT29 in vaccine research theft operations (2020), documented by CISA, NSA, NCSC UK, and CSE Canada in a joint advisory. The specific combination of language (Go), communication protocol implementation, and C2 structure was unique to this actor.
**EnvyScout → BoomBox → NativeZone → VaporRage:**The 2021 USAID phishing campaign used a consistent infection chain across thousands of targets, with each stage precisely crafted to drop the next. The multi-stage architecture, the specific abuse of the USAID SendGrid account for initial delivery, and the custom malware stages constitute a TTP fingerprint.
**Operational patience:**APT29 is consistently documented maintaining access for months before acting. The SolarWinds implant was dormant for up to two weeks; post-activation activity proceeded slowly over months to avoid detection. This operational patience — which requires significant resources and discipline — is a behavioral fingerprint.
Operator Mistakes (strongest — documented instances)
Mistake 1: SUNBURST staging domain
The SUNBURST backdoor communicated via DNS using a domain (avsvmcloud[.]com) that was legitimately registered and controlled by SolarWinds. The adversary subverted the SolarWinds update mechanism so that compromised clients would reach out to actor-controlled subdomains of this legitimate domain. The operational security failure: when FireEye began investigating (after their own breach via SUNBURST), the actor's network infrastructure remained connected to the malware's operation long enough to be analyzed. The kill switch domain was registered by FireEye and Microsoft, immediately disabling the backdoor in all deployed instances — revealing the actor's dependence on that single domain as an OPSEC weakness.
Mistake 2: Dutch AIVD CCTV footage — the most remarkable operator mistake in public CTI history
In 2017, Dutch intelligence service AIVD had penetrated APT29’s network (specifically their operational server in Moscow), giving them real-time visibility into APT29 operations. AIVD had also gained access to the CCTV camera in the building’s lobby, which allowed them to photograph individuals entering APT29’s operational office. When APT29 later attacked the U.S. Democratic National Committee, AIVD was watching in real time and was able to alert the NSA. This is the ultimate operator mistake category: physical security failure enabling the adversary to be physically identified.
Mistake 3: Compilation environment consistency
Across the Dukes malware family, malware samples compiled over a multi-year period show compilation timestamps clustering in a timezone consistent with Moscow Standard Time, during weekday business hours, with a clear reduction during Russian national holidays. This temporal fingerprint, maintained consistently across years of operations, represents an operator mistake of habit — the development team did not sanitize compilation timestamps or rotate their working hours to obscure timezone attribution.
Mistake 4: SolarWinds victim beacon timing
During the active phase of SUNBURST, the malware beaconed out to C2 infrastructure at intervals calibrated to evade detection tools. But the timing ofoperator responsesto beacon check-ins — when a human on the other end received a beacon and decided to proceed with manual hands-on-keyboard activity — clustered during Moscow business hours. The adversary’s operational response time was itself a timezone fingerprint.
10. Splitting Findings: Confirmed / Assessed / Weak / Noise
This is the core analytical discipline of attribution. Every piece of evidence must be categorized before it can be included in an attribution case.
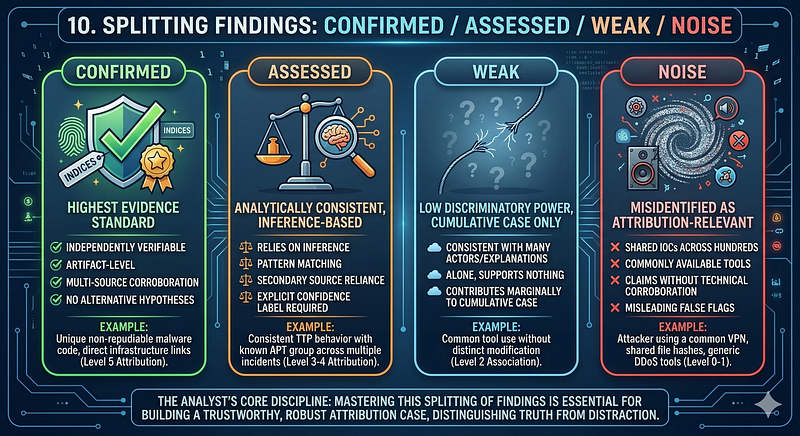
The Four Categories
CONFIRMED— Evidence that meets a high evidentiary standard: independently verifiable, artifact-level, not dependent on single-source reporting, not explainable by alternative hypotheses.
ASSESSED— Evidence that is analytically consistent with the attribution but relies on inference, pattern matching, or secondary sources that cannot be fully independently verified. Requires explicit confidence labeling.
WEAK— Evidence that is consistent with many different actors or explanations. Alone, it supports nothing. In combination with stronger evidence, it contributes marginally to a cumulative case.
NOISE— Evidence that has been misidentified as attribution-relevant. IOCs shared across hundreds of actors. Commonly available tools. Claims without technical corroboration.
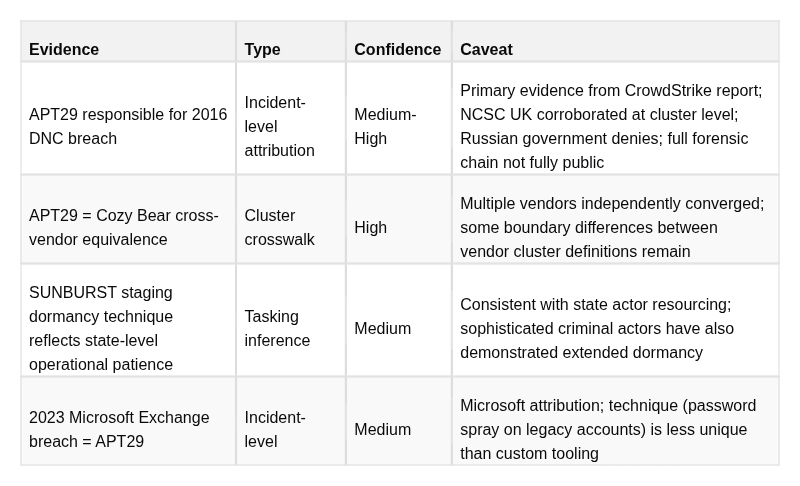
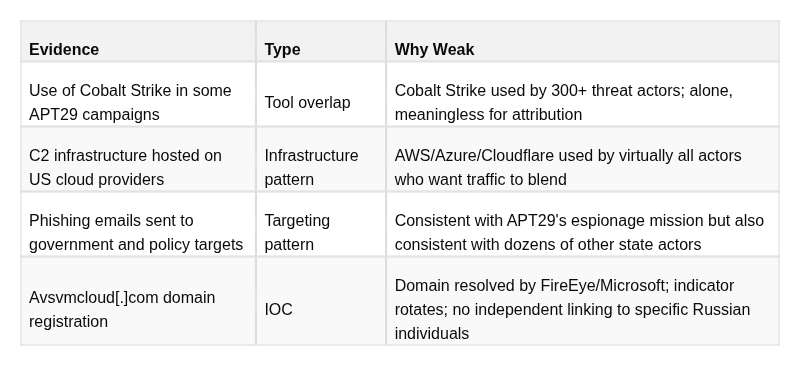
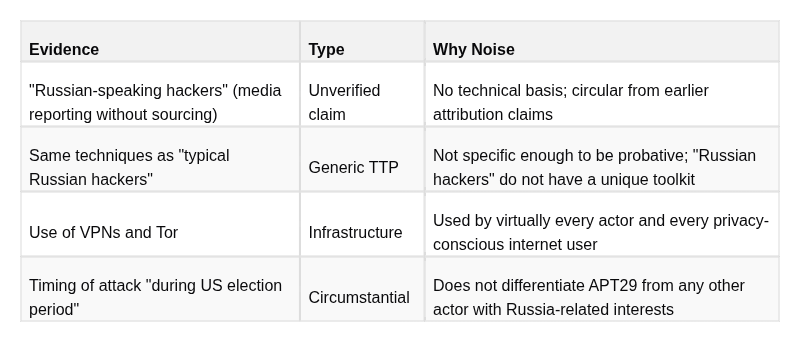
APT29 Evidence Split
CONFIRMED
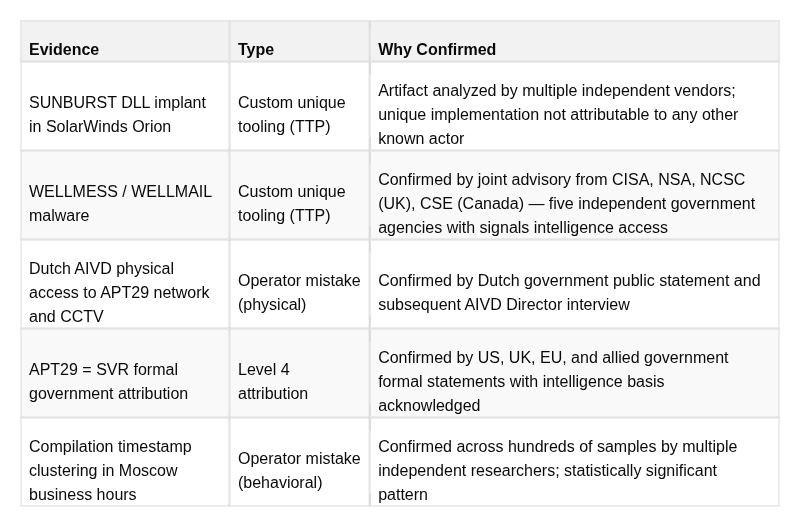
ASSESSED
WEAK (Contributes only in aggregate)
NOISE
11. How to Articulate Attribution: Valid and Uncertain
The Attribution Statement Template
A well-constructed attribution statement has four components:
[ACTOR NAME]
is attributed with
[CONFIDENCE LEVEL]
confidence
to
[INCIDENT/CAMPAIGN]
based on
[EVIDENCE SUMMARY]
.
Residual uncertainty exists regarding
[SPECIFIC UNCERTAINTY]
.
Example: APT29 / SolarWinds
Strong version (correct):
> “We attribute the SolarWinds Orion supply chain compromise (December 2020) to APT29 (Cozy Bear), acting on behalf of Russia’s Foreign Intelligence Service (SVR), with high confidence.
> Attribution basis: (1) The SUNBURST implant is a custom-developed tool uniquely associated with APT29’s long-running Dukes malware family, confirmed by artifact analysis across five independent vendor investigations. (2) Operational tempo and victim selection (government agencies, policy research organizations, defense contractors) is consistent with SVR’s documented collection priorities. (3) Infrastructure provisioning patterns — use of legitimate cloud providers as C2, dormancy techniques to avoid sandbox detection — match APT29’s established operational tradecraft. (4) Formal attribution by CISA, NSA, FBI (Joint Statement Jan 5, 2021) and NCSC UK provides government-level corroboration with acknowledged signals intelligence basis.
> Residual uncertainty: — Incident-level attribution to a specific SVR unit or individual officers has not been publicly established (contrast: GRU Unit 74455 indictment for Sandworm). — A sophisticated false flag operation cannot be fully excluded, though the operational scope, duration (months of SUNBURST dormancy), and resource requirements make this hypothesis low-probability. — The degree to which SVR leadership directed specific target selection vs. delegated to operational teams is unknown. ”
Weak version (incorrect):
> “Russia hacked SolarWinds.”
The Uncertainty Is Not a Weakness
Many analysts avoid expressing uncertainty because they fear it undermines the credibility of their attribution. The opposite is true.**Confidence statements without uncertainty bounds are not credible to sophisticated consumers.**An intelligence report that presents attribution as certain when it is not will be discounted by experienced readers who know that certainty in attribution is almost never achievable.
The correct framing:“We are highly confident in cluster-level attribution. We are less confident at the incident level. The following specific elements remain uncertain…”
This framing builds trust precisely because it is honest.
When to Withhold Attribution
Sometimes the honest answer is:“We cannot attribute this with sufficient confidence to publish a finding.”
Withhold attribution when:
-
The primary evidence is IOC-only with no TTP or infrastructure pattern support
-
The attribution is based on single-source reporting that cannot be corroborated
-
The targeting or operational pattern is inconsistent with the claimed actor’s known profile (possible false flag)
-
The evidence could equally support multiple hypotheses and no differentiator exists
Publishing uncertain attribution is worse than no attribution. A false conclusion published with confidence becomes embedded in the intelligence ecosystem and is cited in subsequent reports, creating a recursive citation loop that obscures the weakness of the original evidence.
12. Common Attribution Mistakes
Mistake 1: Circular Citation
**What happens:**Report A attributes an incident to Actor X. Report B cites Report A. Report C cites Reports A and B. Report D states that “multiple sources” attribute the incident to Actor X — and cites A, B, and C. The original single source has been replicated into the appearance of independent corroboration.
**How to detect it:**Trace every citation back to its primary source. Count primary sources, not citation count. If all roads lead to one original report, you have one source of evidence, regardless of how many derivative reports exist.
**How to avoid it:**When writing attribution, document your primary sources explicitly. If your evidence traces to a single origin, acknowledge it. Do not present that evidence as multiply-corroborated when it is not.
Mistake 2: Tool = Actor
**What happens:**Detection of Mimikatz, Cobalt Strike, Metasploit, or any other commodity/widely-used tool is cited as attribution evidence.
**Why it fails:**Credential dumping tools and offensive security frameworks are available to any actor with technical skill and modest resources. They carry zero actor-specific attribution weight.
**The fix:**Focus on configuration, deployment context, adjacent unique tools, and behavioral patterns. Cobalt Strike with a specific malleable C2 profile, deployed via a specific loader, in combination with specific lateral movement techniques — that is a fingerprint. Cobalt Strike alone is noise.
Mistake 3: Temporal Coincidence = Causal Connection
**What happens:**An attack occurs the same week as a geopolitical event. The attribution report notes that “Actor X targeted this organization following [political event], suggesting motivation [Y].”
**Why it fails:**Temporal proximity is not causal evidence. Nation-state actors conduct operations continuously; any specific operation will occur near some geopolitical event by chance.
**The fix:**Timing observations are context, not evidence. Document them, but do not cite them as attribution support.
Mistake 4: Ignoring the False Flag Hypothesis
**What happens:**An analyst finds strong IOC and code overlap with Actor X and concludes attribution without examining whether the evidence could be planted.
How to assess false flag likelihood:
-
Does the victim alignment make sense for Actor X’s known objectives?
-
Is the evidence unusually convenient or easy to find?
-
Would Actor X have an established capability for this specific operation?
-
Are there deep behavioral artifacts (not just surface IOCs) that are consistent with Actor X’s genuine operational style?
**The fix:**Include a brief false flag assessment in every attribution report. State explicitly that you considered the possibility and explain why you assessed it as low-probability (or not).
Mistake 5: Vendor Name ≠ Actor Identity
What happens:“CrowdStrike says this is FANCY BEAR, so it’s FANCY BEAR.” A vendor tracking name is cited as though it is an established identity.
**Why it fails:**Vendor tracking names are internal cluster labels. FANCY BEAR (CrowdStrike), APT28 (Mandiant), Sofacy (Kaspersky), Forest Blizzard (Microsoft), and Sednit (ESET) may or may not represent exactly the same set of incidents. Vendor cluster boundaries differ. None of them independently constitute attribution — they are labels for tracking.
**The fix:**When citing vendor attribution, specify: the vendor name, the tracking label used, what evidence type underlies their assessment, and whether independent corroboration exists. “Multiple vendors independently attribute this cluster to the same activity, with government confirmation” is stronger than citing one vendor’s label.
13. Attribution in Practice: Interview-Ready Frameworks
The Three Questions Every Attribution Assessment Should Answer
When presenting attribution in an interview, a briefing, or a report, structure your analysis around three questions:
**1. What are we attributing?**Be specific: incident attribution or cluster attribution? Which specific campaign, malware family, or operation? What is the date range?
**2. What is the evidence and what type is it?**Classify each piece of evidence: IOC overlap (weak), infrastructure pattern (moderate), TTP consistency (strong), operator mistake (strongest). What is the cumulative picture?
**3. What are the alternative hypotheses and why are we confident in our conclusion over them?**What other actors could explain this evidence? Why does our attributed actor fit better than the alternatives? What would change our assessment?
The “Five-Sentence Attribution”
For rapid communication — interviews, threat intelligence briefings, executive summaries — practice delivering attribution in five sentences:
SENTENCE 1 — THE CONCLUSION:
"We attribute [campaign/incident] to [Actor] with [confidence level] confidence."
SENTENCE 2 - THE STRONGEST EVIDENCE:
"The primary basis is [strongest evidence type]: [specific evidence]."
SENTENCE 3 - CORROBORATING EVIDENCE:
"This is corroborated by [second evidence type] and [third evidence type]."
SENTENCE 4 - THE UNCERTAINTY:
"Residual uncertainty exists regarding [specific element] because [reason]."
SENTENCE 5 - THE IMPLICATION:
"For defenders, this means [actionable implication]."
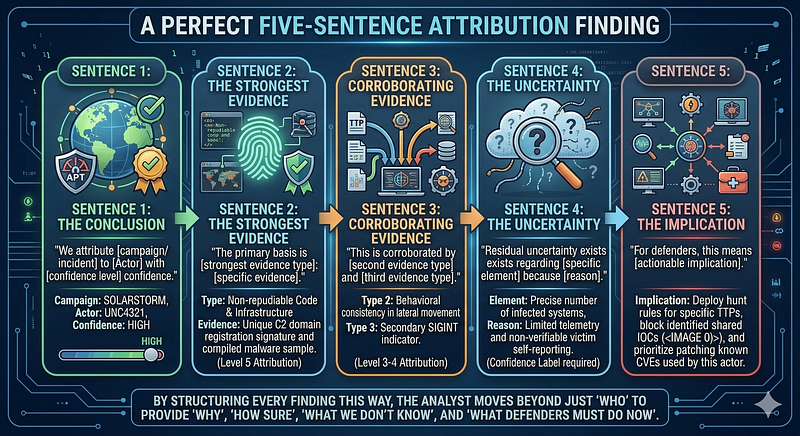
Example — APT29 / SolarWinds:
“We attribute the SolarWinds Orion supply chain operation to APT29 / SVR with high confidence. The primary basis is the SUNBURST backdoor — custom tooling unique to APT29’s Dukes malware lineage, confirmed by artifact analysis across multiple vendors. This is corroborated by operational pattern consistency with APT29’s established tradecraft and formal government attribution by CISA, NSA, FBI, and NCSC UK. Residual uncertainty exists at the incident level regarding specific unit or officer identity within SVR. For defenders, this means prioritizing detection for supply chain compromise vectors and long-dormancy implants consistent with SVR’s patient operational style.”
Sixty words. Covers all four components. Defensible. Honest.
Handling the Hard Questions in an Interview
“How confident are you in this attribution?”→ Use the three-tier model. State your confidence level explicitly and explain what would change it to higher or lower.
“Could this be a false flag?”→ Acknowledge the possibility, explain your assessment of its likelihood, and cite the deep behavioral evidence that is inconsistent with artificial construction.
“Are you saying this was the Russian government?”→ Distinguish cluster attribution (yes) from incident-level attribution (assessed high confidence) from individual identification (not in this case). State what the formal government attribution says and what evidence basis it acknowledges.
“What would make you change your mind?”→ This is the best intelligence question anyone can ask. Have an answer: “Evidence that the SUNBURST code was available to other actors prior to this operation; evidence of a different actor’s infrastructure in the pre-compromise phase; operator behavior inconsistent with known SVR operational patterns.”
14. Quick Reference Cheatsheet
Evidence Type Hierarchy
IOC
OVERLAP
(Weakest)
Use as:
Collection
trigger
only
Never use as:
Attribution
conclusion
Why weak:
Shared
hosting,
false
flags,
rotating
infrastructure
INFRASTRUCTURE
REUSE
(Moderate)
Use as:
Supporting
evidence
alongside
stronger
types
Best indicators:
Hosting
preferences,
certificate
patterns,
domain
naming
Why caveatable:
Can
be
shared
between
actors;
can
be
deliberately
mimicked
TTP
CONSISTENCY
(Strong)
Use as:
Core
attribution
evidence
Best indicators:
Custom
unique
tooling,
unique
operational
sequences
Why strong:
Operationally
expensive
to
change;
reflects
training
and
habit
Still caveatable:
Tool
sharing
exists;
framework
use
is
non-attributive
OPERATOR
MISTAKES
(Strongest)
Use as:
Gold
standard
evidence
-
cite
explicitly
and
prominently
Categories:
Language
artifacts,
timezone
patterns,
OPSEC
failures,
unique
code
fingerprints,
personnel
linkages
Why strongest:
Cannot
be
fabricated
convincingly;
unintentional
Attribution Confidence Levels
HIGH — Multiple independent streams;
at
least
one
strong evidence type;
government corroboration
or
unique
tool confirmation
MEDIUM — Consistent
with
attribution; TTP
or
infrastructure
match
;
alternative hypotheses exist but
are
less probable
LOW — Suggestive
only
; IOC
-
heavy; single
-
source; many alternatives
Attribution Statement Components
1.
ACTOR — With tracking name and vendor source
2.
CAMPAIGN — Specific, date-bounded
3.
CONFIDENCE — Explicit tier (High/Medium/Low)
4.
EVIDENCE SUMMARY — Strongest evidence first, classified by type
5.
UNCERTAINTY — What remains unconfirmed, and why
6.
ALTERNATIVE HYPOTHESES — What you considered and why you rejected
7.
IMPLICATION — What this means for defenders
Red Flags That Suggest False Flag
□ Evidence
is
unusually easy
to
find
and
perfectly placed
□ Surface IOC match but deep behavioral inconsistency
□ Operation doesn
't align with attributed actor's known objectives
□ Perfectly matching
"mistake"
that real actors would
not
make
□ Code similarity that
is
too high
to
be coincidental (check
for
planted artifacts)
□ Victim
set
inconsistent
with
actor
's established targeting pattern
The Circular Citation Test
For
every
citation
in
your attribution:
1.
What
is
the
primary
source (the
first
report
to
make this claim)?
2.
What evidence did the
primary
source cite?
3.
Is
the
primary
source a government advisory, IR report
with
forensic access,
or
a vendor
with
artifact
-
level analysis?
4.
How many truly independent sources (
with
independent evidence access) agree?
If answers: "one report, citing itself, no artifacts, zero independent confirmation"
→ This is a single source. Label it as such. Do not present it as corroborated.
Conclusion
Attribution is the hardest problem in threat intelligence — and the one most frequently done badly. The analyst who learns to distinguish a smoking gun from a planted clue, who can articulate what their evidence proves and what it doesn’t, and who can deliver a five-sentence attribution that is both confident and honest is doing something rare in this industry.
The four evidence types are a hierarchy, not a checklist. Operator mistakes beat TTP consistency beats infrastructure patterns beats IOC overlap. But the strongest case combines multiple types — confirming that the behavioral fingerprint, the infrastructure pattern, and the unintentional disclosure all point to the same actor.
The discipline is not in saying*“It was Russia.”The discipline is in saying“Here is why we believe it was Russia’s SVR, here is what we’re certain about, here is what we’re inferring, and here is what would change our conclusion.”*
That is what distinguishes a CTI analyst from a security commentator.
Author: Andrey PautovPublished: March 2026Tags: Threat Intelligence, CTI, Attribution, OSINT, APT Analysis, Malware Analysis, Nation-State Threats, SOC
Further Reading
-
Rid, T. & Buchanan, B. (2015).Attributing Cyber Attacks. Journal of Strategic Studies.
-
Rid, T. (2020).Active Measures: The Secret History of Disinformation and Political Warfare.(Chapter on digital attribution methodology)
-
MITRE ATT&CK:attack.mitre.org/groups— Actor profiles with evidence-sourced TTP mappings
-
CISA AA21–008A — SolarWinds attribution advisory:cisa.gov/news-events/cybersecurity-advisories/aa21–008a
-
Kaspersky,Olympic Destroyer False Flag Analysis:securelist.com/olympic-destroyer-is-here-to-trick-the-industry/84295
-
Check Point Research:Bad Karma, No Justice: Void Manticore Destructive Activities in Israel:research.checkpoint.com/2024/bad-karma-no-justice-void-manticore-destructive-activities-in-israel